프로그램 (Program)
컴퓨터에서의 프로그램은 사용자가 원하는 일을 처리할 수 있도록 프로그래밍 언어를 사용하여 올바른 수행절차를 표현해 놓은 명령어들의 집합입니다. 그에 필요한 데이터를 묶어 놓은 파일로 보조 기억장치에 저장되어 있습니다.
예로 Windows의 경우 exe파일입니다.- 컴퓨터에서 어떤 작업을 위해 실행할 수 있는 ‘정적인 상태’의 파일 이라고 볼 수 있습니다.
프로그램은 컴파일러가 컴파일 과정을 거쳐 컴퓨터가 이해할 수 있는 기계어로 번역되어 실행할 수 있는 파일이 되는 것을 의미합니다.
프로그램의 실행은 이 실행파일을 메모리에 로드하고 프로세스로 전환하여 이용하는 것 입니다.
컴퓨터 프로그램
컴퓨터 프로그램은 컴퓨터가 실행할 수 있는 프로그래밍 언어의 명령 시퀀스 또는 집합입니다. 컴퓨터 프로그램은 문서 및 기타 무형 구성요도 포함하는 소프트웨어의 한 구성 요소입니다.
사람이 읽을 수 있는 형태의 컴퓨터 프로그램을 소스 코드라고 합니다. 컴퓨터는 기본 기계 명령만 실행할 수 있기 떄문에 소스 코드를 실행 하려면 다른 컴퓨터 프로그램이 필요합니다. 따라서 소스코드는 언어의 컴파일러를 사용하여 기계 명령어로 번역될 수 있습니다.
- 기계어 프로그램은 어셈블러를 사용하여 번역됩니다.
결과 파일을 실행파일이라고 합니다. 또는 소스 코드가 언어의 인터프리터 내에서 실행될 수 있습니다.
실행 파일의 실행이 요청되면 운영체제는 이를 메모리에 로드하고 프로세스를 시작합니다. 중앙 처리 장치는 곧 이 프로세스로 전환하여 각 기계명령을 가져오고 디코딩한 다음 실행할 수 있습니다.
실행을 위해 소스 코드가 요청되면 운영체제는 해당 인터프리터를 메모리에 로드하고 프로세스를 시작합니다. 다음 인터프리터는 소스 코드를 메모리에 로드하여 각 명령문을 번역하고 실행합니다. 소스 코드를 실행하는 것은 실행 파일을 실행하는 것보다 느립니다. 또한 인터프리터가 컴퓨터에 설치되어 있어야 합니다.

프로그래밍(Programming)
프로그래밍이란 목적에 맞는 알고리즘으로부터 프로그래밍 언어를 사용하여 구체적인 프로그램을 작성하는 과정을 의미합니다. 이렇게 작성된 프로그램은 먼저 실행 파일(executable file)로 변환되어야 실행할 수 있습니다.
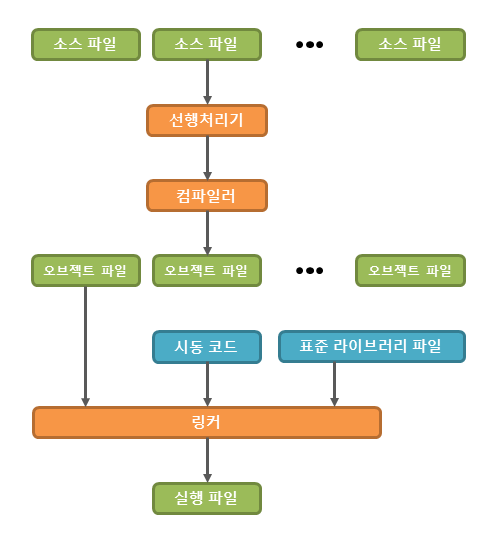
- 소스 파일(source file)의 작성
- 선행처리기(preprocessor)에 의한 선행처리
- 컴파일러(compiler)에 의한 컴파일
- 링커(linker)에 의한 링크
- 실행 파일(executable file)의 생성
프로그래밍에서 가장 먼저 해야 할 작업은 바로 프로그램을 작성하는 것 입니다.
선행처리(preprocess)란 소스 파일 중에서도 선행처리 문자(#)로 시작하는 선행처리 지시문의 처리 작업을 의미합니다. 이러한 선행처리 작업은 선행처리기(preprocessor)가 수행합니다. 선행처리기는 코드를 생성하는 것이 아닌, 컴파일하기 전 컴파일러가 작업하기 좋도록 소스를 재구성해주는 역활만을 합니다.
컴퓨터는 0과 1로 이루어진 이진수로 작성된 기계어만을 이해할 수 있습니다. 소스 파일은 개발자에 의해 C언어로 작성되므로, 컴퓨터는 그것을 바로 이해할 수 없습니다. 따라서 소스 파일을 컴퓨터가 알아볼 수 있는 기계어로 변환시켜야 하는데, 그 작업을 컴파일(compile)이라고 합니다.
컴파일은 컴파일러에 의해 수행되며, 컴파일이 끝나 기계어로 변환된 파일을 오브젝트 파일(object file)이라고 합니다.이러한 오브젝트 파일의 확장자는 .o나 .obj가 됩니다.
컴파일러에 의해 생성된 오브젝트 파일은 운영체제와의 인터페이스를 담당하는 시동 코드(start-up code)를 가지고 있지 않습니다. 또한, 대부분의 C프로그램에서 사용하는 C표준 라이브러리 파일도 포함되어 있지 않습니다.
이때 하나 이상의 오브젝트 파일과 라이브러리 파일, 시동 코드 등을 합쳐 하나의 파일로 만드는 작업을 링크(link)라고 합니다.
링크는 링커(linker)에 의해 수행되며, 링크가 끝나면 하나의 새로운 실행 파일이나 라이브러리 파일이 생성됩니다. 이처럼 여러 개의 소스 파일을 작성하여 최종적으로 링크를 통해 하나의 실행 파일로 만드는 것을 분할 컴파일이라고 합니다.
분할 컴파일
모듈(module)이란 프로그램을 구성하는 구성 요소로, 관련된 데이터와 함수를 하나로 묶은 단위를 의미합니다.
보통 하나의 소스 파일에 모든 함수를 작성하지 않고, 함수의 기능별로 따로 모듈을 구성합니다. 이처람 모듈을 합쳐 하나의 파일로 작성하는 방식으로 프로그램을 만들게 됩니다.
위처럼 프로그램 코드를 기능별로 나눠서 독립된 파일에 저장하여 관리하는 방식을 모듈화 프로그래밍이라 합니다.
분할 컴파일
작성된 모듈(module)은 개별적으로 컴파일된 후, 링커에 의해 하나의 실행 파일로 만들어집니다. 이렇게 하나의 실행 파일을 만들기 위해서 소스 파일을 여러 개로 나누어 개발하는 방식을 분할 컴파일 방식이라 합니다.
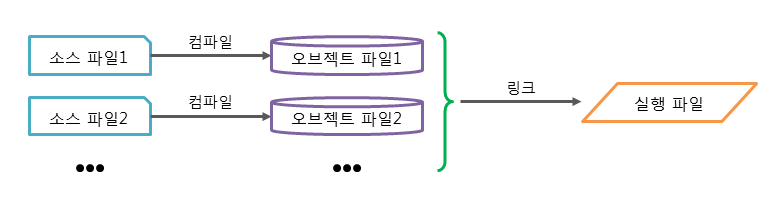
최종적인 실행 파일의 생성을 위해서 접근하는 변수나 호출하는 함수가 어디에 있는지 서로 연결해주는 작업을 링크(link)라고 합니다.
- extern 키워드는 분할 컴파일 방식에서 여러 개의 소스 파일 사이의 상호 참조는 전역 변수와 전역 함수만이 가능합니다. 기본적으로 C컴파일러는 프로그램에 등장하는 전역 변수를 오로지 해당 파일에서만 찾습니다. 따라서 외부 파일에서 참조하는 전역 변수는 컴파일러에게 외부 파일에 존재하는 변수라는 사실을 알려줍니다.
- static 키워드는 분할 컴파일 방식에서 변수의 접근 영역을 해당 파일로만 한정시키고자 할 때는 static키워드를 사용하여 선언하면 됩니다. 이렇게 선언된 변수는 다른 소스 파일에서 extern키워드를 사용해 선언하더라도 접근할 수 없는 전역 변수가 됩니다.
프로세스와 컴파일 과정
프로세스는 프로그램으로부터 인스턴스화(Instantiate)된 것을 말합니다. 에를 들어 프로그램은 구글 크롬 프로그램(chrome.exe)과 같은 실행 파일이며, 이를 두번 클릭하면 구글 크롬 ‘프로세스’가 시작되는 것 입니다.
프로그램은 컴파일러가 컴파일 과정을 거쳐 컴퓨터가 이해할 수 있는 기계어로 번역되어 실행될 수 있는 파일이 되는 것을 의미하며 ‘컴파일 과정’이란 다음과 같습니다. 참고로 여기서 말하는 프로그램이란 C언어 기반의 프로그램을 의마하며, 이는 별도의 컴파일 과정 없이 한 번에 한 줄씩 읽어들여서 실행하는 프로그램인 인터프리터 언어로 된 프로그램과는 다릅니다.
- 선행처리기(pre-processor)에 의한 선행처리
- 컴파일러(compiler)에 의한 컴파일
- 링커(linker)에 의한 링크
- 실행 파일(executable file)의 생성
선행처리기(전처리, pre-processing)
전처리는
- 소스 코드의 주석을 제거하고,
- #include지시문을 만나면 해당하는 헤더 파일을 찾아 헤더 파일에 있는 모든 내용을 복사해서 소스 코드에 삽입합니다.
- 즉, 헤더 파일은 컴파일에 사용되지 않고 소스 코드 파일 내에 전부 복사됩니다. 헤더 파일에 선언된 함수 원형은 후에 링킹 과정을 통해 실제로 함수가 정의되어 있는 오브젝트 파일(컴파일된 소스 코드 파일)과 결합합니다.
- 매크로 치환 및 적용합니다. #define 지시문에 정의된 매크로를 저장하고 같은 문자열을 만나면 #define된 내용으로 치환합니다. 간단하게 말해 매크로 이름을 찾아서 정의한 값으로 전부 바꿔줍니다.
컴파일(Compilation)과정
컴파일(Compilation)과정은 컴파일러(Compiler)를 통해 전처리된 소스 코드 파일(.i)을 어셈블리어 파일 (.s)로 변환하는 과정입니다.
이 과정에서 우리가 일반적으로 컴파일하면 생각하는 언어의 문법 검사가 이루어집니다. 또한 static한 영역(Data, BSS영역)들이 메모리 할당을 수행합니다.
- 컴파일러는 오류 처리, 코드 최적화 작업을 하며 어셈블리어로 변환합니다.
컴파일러 구조
컴파일러는 세 단계(프론트 엔드 - 미들 엔드 - 백 엔드)로 구성되어 있습니다.

프론트엔드(Front-end)
프론트엔드에서는 언어 종속적인 부분을 처리합니다.
소스 코드가 해당 언어로 올바르게 작성되었는지 확인하고 미들엔드에 넘겨주기 위한 GIMPLE 트리(소스 코드를 트리 형태로 표현한 자료 구조)를 생성합니다.
이 과정에서 C, C++, Java와 같은 다양한 언어들이 각 언어에 맞게 처리된 후 공통된 중간 표현인 GIMPLE 트리로 변환되므로 언어 종속적인 부분을 처리할 수 있습니다.
미들엔드(Middle-end)
미들엔드에서는 아키텍쳐 비종속적인 최적화를 수행합니다.
아키텍쳐 비종속적인 최적화란 CPU아키텍쳐가 무엇이든(arm, x86 등) 상관없이 할 수 있는 최적화를 말합니다. 프론트엔드에서 넘겨받은 GIMPLE 트리를 이용해 아키텍쳐 비종속적인 최적화를 수행한 후 백엔드에서 사용하는 RTL(Register Transfer Language, 고급 언어와 어셈블리 언어의 중간 형태)를 생성합니다.
백엔드(Back-end)
백엔드에서는 아키텍쳐 종속적인 최적화를 수행합니다.
아키텍쳐 종속적인 최적화란 아키텍쳐 특성에 따라 최적화를 수행하는 것을 말합니다. 같은 기능을 수행하는 명령이여도 CPU 아키텍쳐별로 더욱 효율적인 명령어로 대체하여 성능을 높이는 작업을 예를 들 수 있습니다.
미들엔드에서 넘겨받은 RTL을 이용해 아키텍쳐 종속적인 최적화를 수행하고 최적화가 완료되면 어셈블리 코드를 생성합니다.
아키텍쳐 종속적인 최적화를 수행하면 해당 아키텍쳐만 이해할 수 있는 언어가 되기 때문에 아키텍쳐가 맞지 않으면 어셈블리 코드를 해석할 수 없습니다.
어셈블리어 정의
기계어는 다른 말로 명령어(Machine Instruction)이라고 부르는데 명령어는 0101010과 같은 이진수로 이뤄진 숫자로 CPU종류마다 고유한 내용을 가지고 있습니다.
어셈블리어는 이런 명령어를 사람이 이해할 수 있게 부호화한 것으로 CPU 명령어(기계어)와 1대1로 매칭됩니다.
많은 컴파일러가 앞서 설명한 세 단계의 구조를 따르고 있지만, 컴파일러마다 차이가 존재한다.
- GNU에서 만든 C 컴파일러인 gcc는 프론트엔드/미들엔드/백엔드 단계가 깔끔하게 분리되어 있지 않고 의존성이 존재합니다.
- 그에 비해 오픈 소스 C 컴파일러인 Clang(프론트엔드) + LLVM(미들엔드, 백엔드)는 단계가 잘 분리되어 있습니다.
어셈블리(Assembly)과정

어셈블리(Assembly)과정은 어셈블러(Assembler)를 통해 어셈블리어 파일(.s)을 오브젝트 파일(.o)로 변환하는 과정입니다.
오브젝트 파일(Object file) 정의
어셈블리 코드는 이제 더 이상 사람이 알아볼 수 없는 기계어로 변환되는데 이를 오브젝트 코드(Object code, 목적 코드)라 부릅니다.
오브젝트 코드로 구성된 파일을 오브젝트 파일(Object File)이라 부르며 이 오브젝트 파일은 특정한 파일 포맷을 가집니다.
- 오브젝트 파일 포맷의 종류는 Windows의 경우 PE(Protable Executable), Linux의 경우 ELF(Executable and Linking Format)로 나눠집니다.
오브젝트 파일 포맷(Object File Foramt)

오브젝트 파일 헤더(Object File Header)는 오브젝트 파일의 기초 정보를 가지고 있는 헤더입니다.
텍스트 섹션(Text Section)은 기계어로 변환된 코드가 들어 있는 부분입니다.
데이터 섹션(Data Section)은 데이터(전역 변수, 정적 변수)가 들어 있는 부분입니다.
심볼 테이블 섹션(Symbol Table Section)은 소스 코드에서 참조되는 심볼들의 이름과 주소가 정의 되어 있는 부분입니다.
재배치 정보 섹션(Relocation Information Section)은 링킹 전까지 심볼의 위치를 확정할 수 없으므로 심볼의 위치가 확정 나면 바꿔야 할 내용을 적어놓은 부분입니다.
디버깅 정보 섹션(Debugging Information Section)은 디버깅에 필요한 정보가 있는 부분입니다.
- 링커는 프로그램 내에 있는 라이브러리 함수 또는 다른 파일들과 목적 코드를 결합하여 실행 파일을 만듭니다. 실행 파일의 확장자는 .exe 또는 .out이라는 확장자를 갖습니다.
심볼 테이블 섹션과 재배치 섹션
심볼(Symbol)은 함수나 변수를 식별할 때 사용하는 이름으로 심볼 테이블(Symbol Table) 안에는 오브젝트 파일에서 참조되고 있는 심볼 정보(이름과 데이터의 주소 등)을 가지고 있습니다.
이때 오브젝트 파일의 심볼 테이블에는 해당 오브젝트 파일의 심볼 정보만 가지고 있어야 하기 때문에 다른 파일에서 참조되고 있는 심볼 정보의 경우 심볼 테이블에 저장할 수 없습니다.

이 소스 코드 파일을 컴파일하여 오브젝트 파일을 생성할 수 있습니다.
하지만 이 오브젝트 파일은 독립적으로 실행할 수 없습니다. 이 파일 안에는 printf 함수를 구현한 내용이 없기 때문입니다.
전처리 과정을 통해 #include
즉, 이 오브젝트 파일을 실행하기 위해서는 printf 함수를 사용하는 오브젝트 파일과 printf 함수를 구현한 오브젝트 파일(libc.a 라이브러리)을 연결시키는 작업이 필요합니다.
이러한 연결 과정을 링킹(Linking)이라고 부릅니다.
링킹(Linking) 과정

링킹(Linking) 과정은 링커(Linker)를 통해 오브젝트 파일(*.o)들을 묶어 실행 파일로 만드는 과정입니다.
이 과정에서 오브젝트 파일들과 프로그램에서 사용하는 라이브러리 파일들을 링크하여 하나의 실행 파일을 만듭니다.
이때 라이브러리를 링크하는 방법에 따라 정적 링킹(Static Linking)과 동적 링킹(Dynamic Linking)으로 나눌 수 있습니다.
링커의 역활
링커의 역활은 크게 심볼 해석과 재배치로 나눌 수 있습니다.

심볼 해석(Symbol Resolution)은 각 오브젝트 파일에 있는 심볼 참조를 어떤 심볼 정의에 연관시킬지 결정하는 과정입니다. 여러 개의 오브젝트 파일에 같은 이름의 함수 또는 변수가 정의되어 있을 때 어떤 파일의 어떤 함수를 사용할지 결정합니다.
재배치(Relocation)는 오브젝트 파일에 있는 데이터의 주소나 코드의 메모리 참조 주소를 알맞게 배치하는 과정입니다. 링커가 컴파일러가 생성한 오브젝트 파일을 모아서 하나의 실행 파일을 만들 때, 각 오브젝트 파일에 있는 데이터의 주소나 코드의 메모리 참조 주소가 링커에 의해 합쳐진 실행 파일에서의 주소와 다르기 때문에 그것을 알맞게 수정해줘야 합니다.
이를 위해 오브젝트 파일 안에 재배치 정보 섹션(Relocation Information Section)이 존재합니다. 링킹 과정에서 같은 세션끼리 합쳐진 후 재배치가 일어납니다.
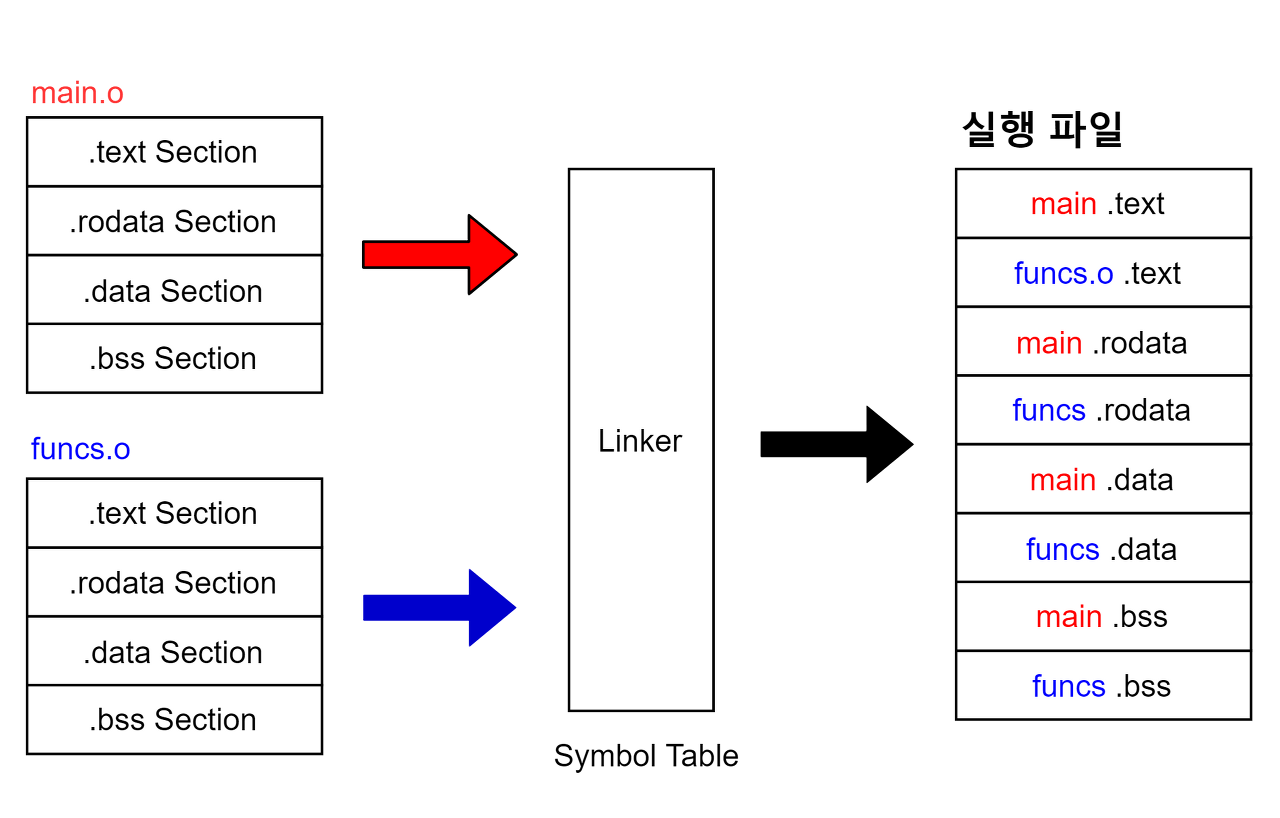
위 그림을 통해 알 수 있듯이 오브젝트 파일 형식은 링킹 과정에서 링커가 여러 개의 오브젝터 파일들을 하나의 실행 파일로 묶을 때 필요한 정보를 효율적으로 파악할 수 있는 구조입니다.
링킹을 하기 전 오브젝트 파일을 재배치 가능한 오브젝트 파일(Relocatable Object File)이라 부르고 링킹을 통해 만들어지는 오브젝트 파일을 실행 가능한 오브젝트 파일(Executable Object File)이라 부릅니다.
프로세스(Process)
프로세스(Process)는 컴퓨터에서 실행되고 있는 프로그램을 말하며 CPU 스케줄링의 대상이 되는 작업(task)이라는 용어와 거의 같은 의미로 쓰입니다. 프로그램이 메모리에 올라가면 프로세스가 되는 인스턴스화가 일어납니다. 이후 운영체제의 CPU 스케줄러에 따라 CPU가 프로세스를 실행합니다.
- 프로그램이 실행되서 돌아가고 있는 상태, 컴퓨터에서 연속적으로 실행되고 있는
동적인 상태의 컴퓨터 프로그램입니다. - 작업관리창에 표시되어 있는 것들이 동적인 상태의 프로그램입니다.
프로그램이 메모리에 올라가면 프로세스가 되는 인스턴스화가 일어나고, 이후 운영체제의 CPU 스케줄러에 따라 CPU가 프로세스를 실행합니다.
- 프로세스는 운영체제가 메모리 등의 필요한 자원을 할당해준
실행중인 프로그램입니다. 프로그램을 실행하면 운영체제로부터 실행에 필요한 자원을 할당받아프로세스가 됩니다. - 프로세스가 할당받는 시스템 자원의 예로, CPU 시간, 운영되기 위해 필요한 주소 공간, Code, Data, Stack, Heap의 구조로 되어있는 독립된 메모리 영역이 있습니다.
프로세스의 특징
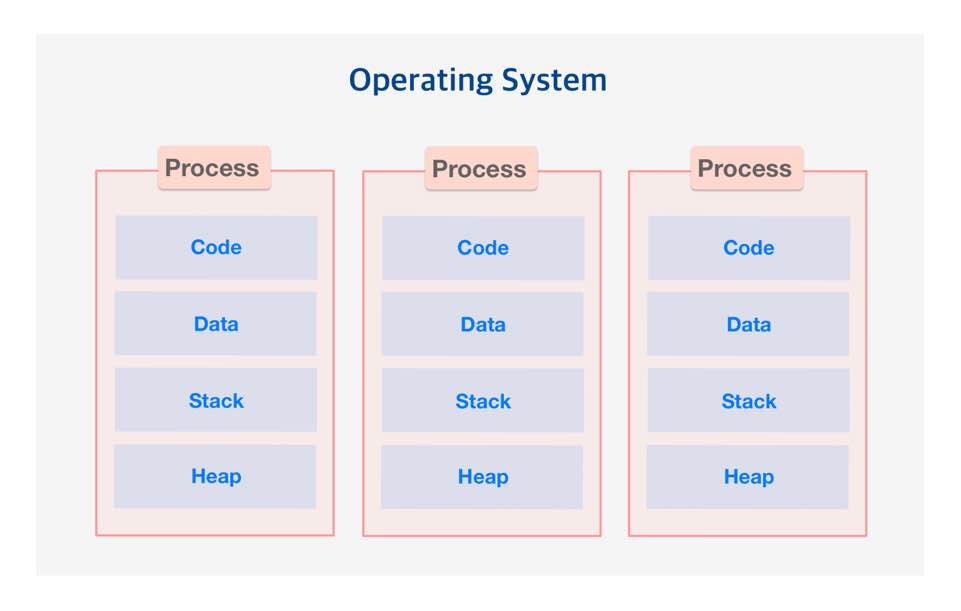
프로세스의 특징으로 운영 체제 (Operating System)에서
- 프로세스는 각각 Code, Data, Stack, Heap의 구조로 되어있는 독립된 메모리 영역을 할당 받습니다.
- 각 프로세스는 별도의 주소 공간에서 실행되며, 서로 독자적인 메모리 공간을 갖기 때문에 서로 메모리 공간을 공유할 수 없습니다. 즉, 다른 프로세스의 변수나 자료구조에 접근할 수 없습니다.
- 다른 프로세스의 자원에 접근하려면 프로세스간의 통신(IPC)을 사용해야합니다.
- 프로세스는 최소 하나 이상의 스레드를 포함합니다.
프로세스의 상태
프로세스의 상태는 여러 가지 상태 값을 갖습니다.
- 생성 상태
- 생성 상태(craete)는 프로세스가 생성된 상태를 의미하며 fork()또는 exec()함수를 통해 생성합니다. 이때 PCB가 할당됩니다.
fork()는 부모 프로세스의 주소 공간을 그대로 복사하며, 새로운 자식 프로세스를 생성하는 함수입니다. 주소 공간만 복사할 뿐이지 부모 프레스의 비동기 작업 등을 상속하지는 않습니다.exec()는 새롭게 프로세스를 생성하는 함수입니다.
- 대기 상태(ready)는 메모리 공간이 충분하면 메모리를 할당받고 아니면 아닌 상태로 대기하고 있으며 CPU 스케줄러부터 CPU 소유권이 넘어오기를 기다리는 상태입니다.
- 대기 중단 상태(ready suspended)는 메모리 부족으로 일시 중단된 상태입니다.
- 실행 상태(running)는 CPU 소유권과 메모리를 할당받고 인스트럭션을 수행 중인 상태를 의미합니다. 이를 CPU burst가 일어났다고도 표현합니다.
- 중단 상태(blocked)는 어떤 이벤트가 발생한 이후 기다리며 프로세스가 차단된 상태입니다. I/O 디바이스에 의한 이터럽트로 이런 현상이 많이 발생하기도 합니다.
- 예를 들어 프린트 인쇄 버튼을 눌렀을 때 프로세스가 잠깐 멈춘 듯한 때가 바로 그 상태입니다.
- 일시 중단 상태(blocked suspended)는 대기 중단과 유사합니다. 중단된 상태에서 프로세스가 실행되려고 했지만 메모리 부족으로 일시 중단된 상태입니다.
- 종료 상태(terminated)는 메모리와 CPU 소유권을 모두 놓고 가는 상태를 말합니다. 종료는 자연스럽게 종료되는 것도 있지만 부모 프로세스가 자식 프로세스를 강제시키는 비자발적 종료(abort)로 종료되는 것도 있습니다. 자식 프로세스에 할당된 자원의 한계치를 넘어서거나 부모 프로세스가 종료되거나 사용자가 process.kill 등 여러 명령어로 프로세스를 종료할 때 발생합니다.
옛날엔 컴퓨터가 한번에 하나의 동작밖에 수행하지 못했습니다. 하지만 다중 작업을 가능하게하는 멀티태스킹 기능이 나오면서 컴퓨터가 프로세스 여러개를 함께 돌리는 것이 가능해졌습니다.
- 프로세서는 컴퓨터 내에서 프로그램을 수행하는 하드웨어 유닛입니다. 이는 중앙 처리 장치(CPU)를 뜻하며, 명령어를 해석하는 컴퓨터의 한 부분입니다.
- 멀티 프로세싱은 여러 개의 프로세스를 사용하는 것을 의미합니다.
- 멀티 태스킹은 같은 시간에 여러 개의 프로그램을 띄우는 것 입니다.
동시성(Concurrency)
프로세서는 원래 한번에 하나의 프로세스만 실행시킬 수 있습니다. 때문에 동시성은 프로세서 하나가 프로그램 1, 2, 3, 4 여러 작업을 돌아가며 일부분씩 수행하는 방식입니다.
이렇게 진행중인 작업을 바꾸는 걸 Context Switching이라고 부릅니다. 이 과정이 매우 빠른 속도로 돌아가게 되면서 사람들에게는 이 프로세스들이 동시에 진행되는 것 처럼 보입니다.
병렬성(Parallelism)
병렬성은 프로세서 하나에 코어 여러개가 달려서 각각 동시에 작업을 하는 방식입니다. 듀얼코어, 쿼드코어, 옥타코어와 같은 명칭의 프로세서가 달린 컴퓨터에서 할 수 있는 방식입니다.
- 코어를 여러개 달아 작업을 분담하게 만든 것 입니다.
프로세스(Process)와 쓰레드(Thread)
프로세스는 스레드의 컨테이너입니다. 스레드의 정보를 담고있는 것에 불과합니다.
프로세스는 각 작업(Task)마다 운영체제로부터 자원을 할당받기 위해 시스템 콜을 하는 부담이 생기지만 멀티 스레드를 사용한다면 시스템 콜을 한번만 해도 되기 때문에 효율적입니다.
또한 IPC방식보다는 스레드 간 통신이 덜 복잡하고 시스템 자원 사용이 더 적으므로 통신의 부담도 줄일 수 있습니다.
| 차이점 | 프로세스 | 스레드 |
|---|---|---|
| 정의 | 실행중인 프로그램 | 프로세스의 실행단위 |
| 생성/종료시간 | 많은 시간 소요 | 적은 시간 소요 |
| 컨텍스트 전환 | 많은 시간 소요 | 적은 시간 소요 |
| 상호작용 | IPC사용 | 공유 메모리 사용 |
| 자원 소모 | 많음 | 적음 |
| 독립성 | 각각 독립적 | 스택만 독립적이고 이외에는 공유 |
멀티프로세스와 멀티쓰레드
멀티 프로세싱이란
하나의 응용프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업(태스크)을 처리하도록 하는 것 입니다.
멀티 프로세싱의 장점
여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상이므로 다른 영향이 확산되지 않습니다.
멀티 프로세스의 단점
Context Switching과정에서 캐쉬 메모리 초기화 등 무거운 작업이 진행되고 많은 시간이 소모되는 등의 오버헤드가 발생하게 됩니다.
프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 프로세스 사이에서 공유하는 메모리가 없어, Context Switching가 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 합니다.
프로세스 사이의 어렵고 복잡한 통신 기법(IPC)으로 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없습니다.
멀티 스레딩이란
하나의 응용프로그램을 여러 개의 스레드로 구성하고 각 스레드로 하여금 하나의 작업을 처리하도록 하는 것 입니다.
윈도우, 리눅스 등 많은 웅영체제들이 멀티 프로세싱을 지원하고 있지만 멀티 스레딩을 기본으로 하고 있습니다.
웹 서버는 대표적인 멀티 스레드 응용 프로그램입니다.
멀티 스레딩의 장점
시스템의 자원 소모 감소합니다. 즉 자원의 효율성 증대합니다. 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있습니다.
시스템 처리량이 증가합니다. 즉 처리 비용 감소합니다. 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 됩니다. 스레드 사이의 작업량이 작아 Context Switching이 빠릅니다.
간단한 통신 방법으로 인한 프로그램 응답 시간 단축합니다. 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적습니다.
멀티 스레딩의 단점
주의 깊은 설계가 필요합니다. 또한 디버깅이 까다롭습니다. 단일 프로세스 시스템의 경우 효과를 기대하기 여럽습니다. 다른 프로세스에서 스레드를 제어할 수 없습니다. 멀티 스레드의 경우 자원 공유의 문제가 발생합니다. 하나의 스레드에 문제가 발생하면 전체 프로세스가 영향을 받습니다.
멀티 프로세스 대신 멀티 쓰레드를 사용하는 이유는?
프로그램을 여러개 키는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이 더 낫기 때문입니다.
자원의 효율성 증대
멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있습니다.
스레드는 프로세스 내의 메모리를 공유하고 때문에 독립적인 프로세스와 달리 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 됩니다.
처리 비용 감소 및 응답 시간 단축
또한 프로세스 간읜 통신(IPC)보다 스레드 간의 통신의 비용이 적으므로 작업들 간의 통신의 부담이 줄어든다.
스레드는 Stack영역을 제외한 모든 메모리를 공유하기 때문에 프로세스 간의 전환 속도보다 스레드 간의 전환 속도가 빠릅니다. Context Switching시 스레드는 Stack 영역만 처리하기 때문입니다.
프로세스의 메모리 구조
운영체제는 프로세스에 적절한 메모리를 할당하는데 다음 구조를 기반으로 할당합니다.

프로세스의 주소 공간은 코드(code), 데이터(data), 스택(stack), 힙(heap)영역으로 구성됩니다. 이러한 주소 공간을 우리는 가상 메모리(또는 논리적 메로리: logical memory)라고 부릅니다.
| 영역 | 설명 |
|---|---|
| Code | 사용자가 작성한 프로그램 함수들의 코드가 CPU에서 수행할 수 있는 기계어 명령 형태로 변환되어 저장되는 공간입니다. 컴파일(compile)타임에 결정되고 중간에 코드를 바꿀 수 없게 Read-Only로 되어있습니다. |
| Data | 전역 변수 또는 static 변수 등 프로그램이 사용하는 데이터를 저장하는 공간입니다. 전역 변수 또는 static 값을 참조한 코드는 컴파일이 완료되면 data 영역의 주소값을 가르키도록 바뀝니다. 전역변수가 변경 될 수도 있어 Read-Write로 되어있습니다. |
| Stack | 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간입니다. 이 영역은 함수 호출시 기록하고 함수의 수행이 완료되면 사라집니다. 메커니즘은 자료구조(stack)에서 배운 LIFO(Last In First Out)방법을 따릅니다. 컴파일 시 stack 영역의 크기가 결정되기 때문에 무한정 할당 할 수 없습니다. 따라서 재귀함수가 반복해서 호출되거나 함수가 지역변수를 메모리를 초과할 정도로 너무 많이 가지고 있다면 stack overflow가 발생합니다. |
| Heap | 프로그래머가 필요할 때마다 사용하는 메모리 영역입니다. Heap영역은 런타임에 결정됩니다. 예를 들어 벡터 같은 동적 배열은 당연히 힙에 동적 할당됩니다. 힙은 ‘동적’인 특징을 가집니다. |
스택(Stack)
스택에는 지역변수, 매개변수, 함수가 저장되고 컴파일 시에 크기가 결정되며 ‘동적’인 특징을 갖습니다.
스택 영역은 함수가 함수를 재귀적으로 호출하면서 동적으로 크기가 늘어날 수 있는데, 이때 힙과 스택의 메모리 영역이 겹치면 안되기 때문에 힙과 스택 사이의 공간을 비워 놓습니다.
데이터 영역(Data)
데이터 영역은 전역변수, 정적변수가 저장되고, 정적인 특징을 갖는 프로그램이 종료되면 사라지는 변수가 들어 있는 영역입니다.
데이터 영역은 BSS영역과 Data 영역으로 나뉘고, BSS영역은 초기화가 되지 않은 변수가 0으로 초기화되어 저장되며 DAta 영역(Data segment)은 0이 아닌 다른 값으로 할당된 변수들이 저장됩니다.
코드 영역(Code)
코드 영역은 프로그램에 내장되어 있는 소스 코드가 들어가는 영역입니다. 이 영역은 수정 불가능한 기계어로 저장되어 있으며 정적인 특징을 가집니다.
힙(Heap)
힙은 동적 할당할 때 사용되며 런타임 시 크기가 결정됩니다. 예를 들어 벡터 같은 동적 배열은 당연히 힙에 동적할당 됩니다. 힙은 ‘동적’인 특징을 가집니다.
스레드 (Thread)
스레드는 프로세스 내에서 프로세스의 자원을 이용해서 실제로 작업을 수행하는 일꾼입니다. 스레드가 소속된 프로세스가 운영체제로부터 자원을 할당받으면 그 자원을 스레드가 사용합니다.
프로세스는 최소 한 개 이상의 스레드를 가지며 이 스레드를 메인 스레드(main thread)라고 합니다.
- 스레드는 작업을 처리하는 논리적인 단위를 말합니다.
- 하나의 코어에 보통 하나의 스레드가 존재하는 것이 일반적이지만 하이퍼 스레딩 기술을 이용해 하나의 코어에 두개의 스레드를 사용하여 성능을 높이는 기술도 존재합니다. 이때 운영체제는 코어를 2개로 인식한다고 합니다.
- 스레드는 프로세스의 실행 가능한 가장 작은 단위입니다.
- 프로세스는 여러 스레드를 가질 수 있습니다.
- 추가적으로 프로그래밍 관점에서 멀티스레드 환경의 경우 CPU가 논리적으로 가지는 스레드 개수만큼 병렬적으로 처리가 되지만 CPU가 논리적으로 가지는 스레드 개수보다 초과되어 스레드 작업이 요청되면 논리적인 스레드 개수 이외의 작업들은 동시성으로 처리가 됩니다.
- 스레드(thread)는 프로세스가 할당 받은 자원을 이용하는 실행 단위이지, 프로세스의 특정한 수행 경로이자 프로세스 내에서 실행되는 여러 흐름의 단위입니다.
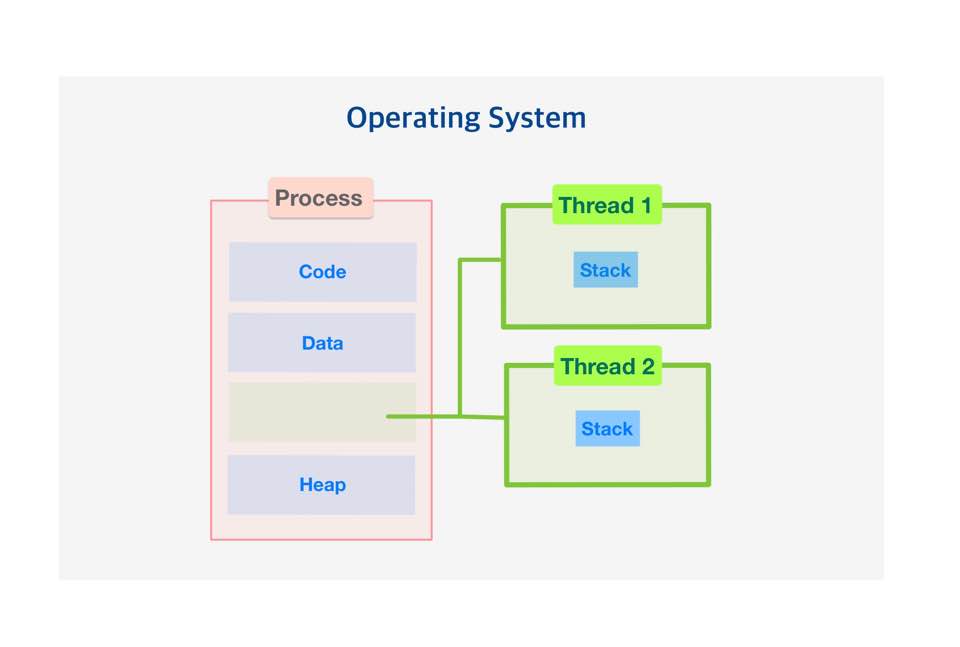
코드, 데이터, 스택, 힙을 각각 생성하는 프로세스와는 달리 스레드는 코드, 데이터, 힙은 스레드끼리 서로 공유합니다. 그 외의 영역은 각각 생성됩니다.
스레드의 특징
각 스레드는 독자적인 스택(Stack) 메모리를 갖습니다.
스레드는 프로세스 내에서 각각 스택만 할당받고 Code, Data, Heap 영역은 공유합니다.
스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소공간이나 자원들을 같은 프로세스 내의 스레드끼리 공유하며 실행됩니다.
각각의 스레드는 별도의 레지스터와 스택을 갖고 있지만, 힙 메모리는 서로 읽고 쓸 수 있습니다.
한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있습니다.
스레드는 메모리를 공유하기 때문에 동기화, 데드락 등의 문제가 발생 할 수 있습니다.
스레드는 대부분의 현대 운영체제가 지원하고 있으며, 이와 관련된 주요 라이브러리로는 POSIX Pthreads, Windows threads, Java threads가 있습니다.
멀티스레딩
멀티스레딩은 프로세스 내 작업을 여러 개의 스레드, 멀티 스레드로 처리하는 기법이며 스레드끼리 서로 자원을 공유하기 때문에 효율성이 높습니다. 예를 들어 웹 요청을 처리할 때 새 프로세스를 생성하는 대신 스레드를 사용하는 웹 서버의 경우 훨씬 적은 리소스를 소비하며, 한 스레드가 중단(blocked)되어도 다른 스레드는 실행(running) 상태일 수 있기 때문에 중단되지 않은 빠른 처리가 가능합니다. 또한, 동시성에도 큰 장점이 있습니다. 하지만 한 스레드에 문제가 생기면 다른 스레드에도 영향을 끼쳐 스레드로 이루어져 있는 프로세스에 영향을 줄 수 있는 단점이 있습니다.
- 동시성은 서로 독립적인 작업들을 작은 단위로 나누고 동시에 실행되는 것처럼 보여주는 것입니다.
공유 자원(shared resource)
공유 자원은 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 파일, 데이터 등의 자원이나 변수 등을 의미합니다. 이 공유 자원을 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상황을 경쟁 상태(race condition)라고 합니다. 동시에 접근을 시도할 때 접근의 타이밍이나 순서 등이 결괏값에 영향을 줄 있는 상태를 말합니다.
임계 영역
공유 자원에 접근할 때 순서 등의 이유로 결과가 달라지는 영역을 임계 영역(critical section)이라고 합니다. 임계 영역을 해결하기 위한 방법은 크게 뮤텍스, 세마포어, 모니터 세 가지가 있으며, 이 방법 모두 상호 배제, 한정 대기, 융통성이란 조건을 만족합니다.
이 방법에 토대가 되는 메커니즘은 잠금(lock)입니다. 예를 들어 임계 구역을 화장실이라고 가정하면 화장실에 A라는 사람이 들어간 다음 문을 잠급니다. 그리고 다음 사람이 이를 기다리다 A가 나오면 화장실을 쓸 수 있는 것입니다.
- 상호 배제는 한 프로세스가 임계 영역에 들어갔을 때 다른 프로세스는 들어갈 수 없습니다.
- 한정 대기는 특정 프로세스가 영원히 임계 영역에 들어가지 못하면 안됩니다.
- 융통성은 한 프로세스가 다른 프로세스의 일을 방해해서는 안됩니다.
뮤텍스(mutex)
뮤텍스는 공유 자원을 사용하기 전에 선정하고 사용한 후에 해제하는 잠금입니다. 잠금이 설정되면 단른 스레드는 잠긴 코드 영역에 접근할 수 없습니다.
또한 뮤텍스는 하나의 상태(잠금 또는 잠금 해제)만 가집니다.
세마포어(semaphore)
세마포어는 일반화된 뮤텍스입니다. 간단한 정수 값과 두가지 함수 wait(P 함수라고도 함) 및 signal(V 함수라고도 함)로 공유 자원에 대한 접근을 처리합니다.
wait()는 자신의 차례가 올 때까지 기다리는 함수이며, signal()은 다음 프로세스로 순서를 넘겨주는 함수입니다.
프로세스가 공유 자원에 접근하면 세마포어에서 wait() 작업을 수행하고 프로세스가 공유 자원을 해제하면 세마포어에서 signal() 작업을 수행합니다. 세마포어에는 조건 변수가 없고 프로세스가 세마포어 값을 수정할 때 다른 프로세스는 동시에 세마포어 값을 수정할 수 없습니다.
모니터(monitor)
모니터는 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원을 숨기고 해당 접근에 대해 인터페이스만 제공합니다.
앞의 그림처럼 모니터는 모니터큐를 통해 공유 자원에 대한 작업을 순차적으로 처리합니다.
- 모니터는 세마포어보다 구현하기 쉬우며 모니터에서 상호 배제는 자동인 반면에, 세마포어에서는 상호 배제를 명시적으로 구현해야 하는 차이점이 있습니다.
교착 상태(deadlock)
교착 상태(deadlock)는 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 말합니다. 예를 들어 프로세스 A가 프로세스 B의 어떤 자원을 요청할 때 프로세스 B도 프로세스 A가 점유하고 있는 자원을 요청하는 것입니다.
교착상태의 원인
상호 배제는 한 프로세스가 자원을 독접하고 있으며 다른 프로세스들은 접근이 불가능합니다.
점유 대기는 특정 프로세스가 점유한 자원을 다른 프로세스가 오청하는 상태입니다.
비선점은 다른 프로세스의 자원을 강제적으로 가져올 수 없습니다.
환형 대기는 프로세스 A는 프로세스 B의 자원을 요구하고, 프로세스 B는 프로세스 A의 자원을 요구하는 등 서로가 서로의 자원을 요구하는 상황을 말합니다.
교착 상태의 해결 방법
- 자원을 할당할 때 애초에 조건이 성립되지 않도록 설계합니다.
- 교착 상태 가능성이 없을 때만 자원 할당되며, 프로세스당 요청할 자원들의 최대치를 통해 자원 할당 가능여부를 파악하는 ‘은행원 알고리즘’을 씁니다.
- 교착 상태가 발생하면 사이클이 있는지 찾아보고 이에 관련된 프로세스를 한 개씩 지웁니다.
- 교착 상태는 매우 드물게 일어나기 때문에 이를 처리하는 비용이 더 커서 교착 상태가 발생하면 사용자가 작업을 종료합니다. 현대 운영체제는 이 방법을 채택했습니다. 예를 들어 프로세스를 실행시키다 ‘응답 없음’이라고 뜰 때, 교착상태가 발생한 경우에 이와 같은 경우가 발생하기도 합니다.